Causality-Induced Positional Encoding for Transformer-Based Representation Learning of Non-Sequential Features
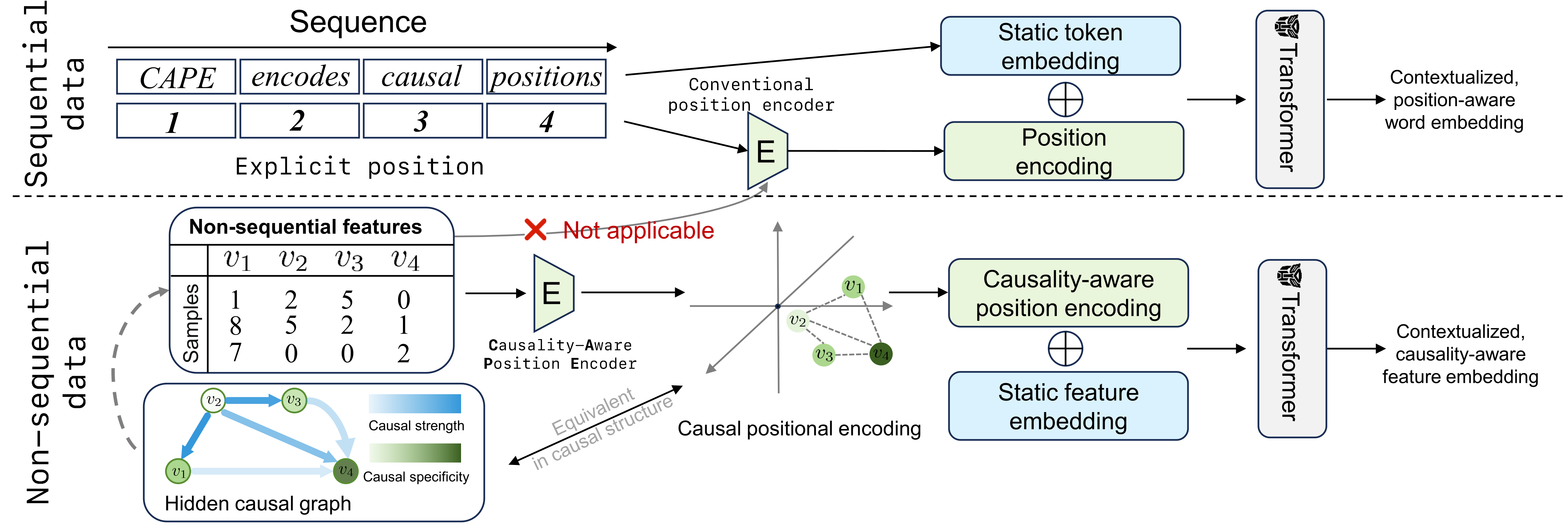
CAPE is a novel positional encoding that identifies underlying causal structure over non-sequential features to improve the performance of transformer-based models.